みなさん、こんにちは大化社員の まめだぬき です。
今回は初心者向けにSQL文の書き方についてまとめてみました!
その中でSQLの基本操作 SELECT文、WHERE句、ORDER BY句、INSERT文、UPDATE文、DELETE文について書き方と使用例を交えて紹介します。
SQLとは「データベースを操作する言語」の事です。
My SQLやSQL Serverなどという言葉があるのでよく混合されがちですがこの2つはデータベースを管理するシステムでSQL自体はデータベース言語なのです。
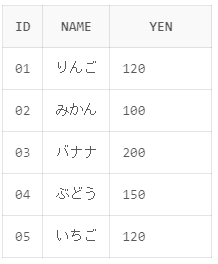
使用するテーブル
今回は使用例にこちらのテーブルを使用していきます。
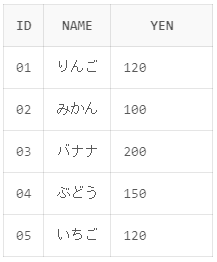
テーブル名(表):shohin
カラム名(列) :id , name , yen
SELECT文
SELECT文とはデータベースからデータの検索・抽出を行います。
書き方:
SELECT [カラム名(列)] FROM [テーブル名(表)]
SELECTは、表示させたいカラム(列)を選びます。
表示させたいカラムが複数ある場合はそれぞれを[ , ](カンマ)でつなぎます。
FORMは、取り出したいテーブル(表)を選びます。
※こちらも表示させたいテーブルが複数ある場合にそれぞれを[ , ](カンマ)でつなぎますが、この複数のテーブルを結合させることをテーブル結合と言います。これは別の機会があれば紹介出来たらと思います。
使用例:
まずは全てのレコード(行)を抽出しようと思います。
SELECT id,name,yen FROM shohin
実行結果:
実行結果のようにテーブルからIDがそれぞれ01,02,03...、nameがりんご,みかん...と全てのレコードを抽出されていることが確認できます。
※テーブルから全てのカラムを指定したい場合は[ * ](アスタリスク)を使用すると全てのカラムを抽出することができます。
書き方:
SELECT * FROM [テーブル名(表)]
指定したいカラムが多い場合や、とりあえずデータを確認したい時に便利です。
WHERE句
where句とはテーブルからデータを抽出する条件指定を行います。
書き方:
SELECT [カラム名(列)] FROM [テーブル名(表)] WHERE [条件]
[条件]には演算子を使ってカラムに条件の値を指定します。
値を指定する時は値を[ ' ](シングルコーテーション)で囲みます。
※値を[ ' ](シングルコーテーション)で囲むと文字として扱います。
使用例:
今回はIDが02のレコードだけ抽出しようと思います。
SELECT id,name,yen FROM shohin WHERE id = '02'
実行結果:
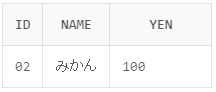
実行結果のようにIDが02のレコードだけが抽出されていることが確認できました。
複数条件
WHERE句で絞り込みの条件が複数必要な場合は条件をそれぞれANDもしくはORでつなぎます。
AND
複数の条件の両方を満たしているレコードを表示させたい場合に使用します。
書き方:
SELECT [カラム名(列)] FROM [テーブル名(表)] WHERE [条件1] AND [条件2]
このように条件1と条件2をAND でつなぐことで条件1と条件2の両方を満たしているレコードのみが表示されます。
使用例:
今回はIDが01かつ120円のレコードを抽出しようと思います。
SELECT id,name,yen FROM shohin WHERE id = '01' AND yen = '120'
実行結果:
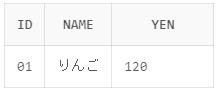
実行結果のようにIDが01で120円のレコードだけが抽出されていることが確認できました。
OR
複数の条件のどちらかが満たしているレコードを表示させたい場合に使用します。
書き方:
SELECT [カラム名(列)] FROM [テーブル名(表)] WHERE [条件1] OR [条件2]
このように条件1と条件2をORでつなぐことで条件1か条件2を満たしているレコードが表示されます。
使用例:
今回はバナナと120円のレコードを抽出しようと思います。
SELECT id,name,yen FROM shohin WHERE name = 'バナナ' OR yen = '120'
実行結果:
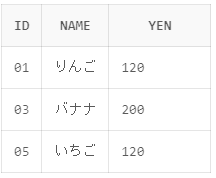
実行結果のようにバナナと120円のレコードが抽出されていることが確認できました。
ORDER BY句
ORDER BY句とはレコードの並び替えを行います。
書き方:
SELECT [カラム名(列)] FROM [テーブル名(表)] ORDER BY [カラム名(列)] [昇順,降順]
ORDER BYの後にカラムを指定することでそのカラムを昇順、降順で並び替えを行います。また、指定したいカラムが複数ある場合はそれぞれを[ , ](カンマ)でつなぎます。
昇順の指定
昇順の指定にはASCを使います。
降順の指定
降順の指定にはDESCを使います。
※昇順降順の指定をしない場合は自動的に昇順になります。
使用例:
今回は円を昇順で並び替えようと思います。
SELECT id,name,yen FROM shohin ORDER BY yen ASC
実行結果:
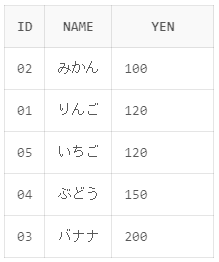
実行結果のように円の昇順で並び替えされていることが確認できました。
WHERE句とORDER BY句の併用
WHERE句とORDER BY句を併用することでテーブルを絞り込みと並び替えが同時に行えます。
書き方:
SELECT [カラム名(列)] FROM [テーブル名(表)] WHERE [条件] ORDER BY [カラム名(列)] [昇順,降順]
WHEREの条件式の後ろにORDER BYを指定します。
使用例:
今回はバナナと120円の商品を抽出し、円を降順で並び替えをしようと思います。
SELECT id,name,yen FROM shohin WHERE name = 'バナナ' OR yen = '120' ORDER BY yen DESC
実行結果:
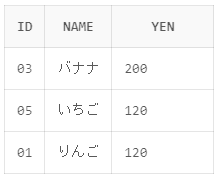
実行結果のようにバナナと120円のレコードのみが抽出され、円の降順に並んでいるのが確認できました。
INSERT文
INSERT文とはレコードの追加を行います。
書き方:
INSERT INTO [テーブル名]([カラム名1],[カラム名2],...) VALUES([値1],[値2],...)
INSERT INTOの後にテーブル名を指定し、カッコでカラムを指定しカラムをそれぞれ[ , ](カンマ)でつなぎます。
VALUESの後ろにカッコでそれぞれ値を指定します値もそれぞれ[ , ](カンマ)でつなぎます。
使用例:
今回はIDが06でレモンを120円でレコードを登録しようと思います。
INSERT INTO shohin (id,name,yen) VALUES('06','レモン','120')
実行結果:

実行結果はこのように1行挿入されたというメッセージが出ます。
ではSELECTしてみましょう。
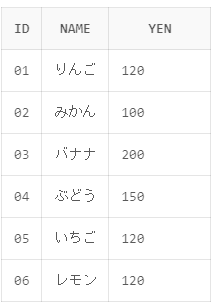
IDが06のレモンのレコードが追加されたのを確認出来ました。
このように左から順にINSERT INTOで指定したカラムから順にVALUESで指定した値が登録されます。
UPDATE文
UPDATE文とはレコードの更新を行います。
書き方:
UPDATE [テーブル名(表)] SET [カラム(列)] = [値] WHERE [条件]
UPDATEの後にテーブル名を指定し、SETの後に変更したいカラムに値を=(イコール)で指定します。
そしてWHEREで絞り込み条件を指定すると条件にあったレコード(行)が更新されます。
使用例:
先程追加したIDが06のレモンの120円を110円に更新しようと思います。
UPDATE shohin SET yen = 110 WHERE id = '06'
実行結果:

実行結果はこのように1行更新されたというメッセージが出ます。
ではSELECTして更新されているか確認してみましょう。
実行結果:
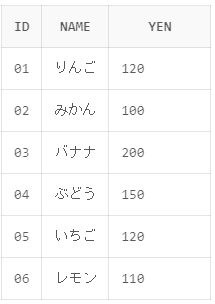
IDが06のレモンが120円から110円に更新されているのを確認できました。
このようにWHEREで条件指定したレコードがSETで指定した更新処理に更新されます。
DELETE文
DELET文とはレコードの削除を行います。
書き方:
DELETE FROM [テーブル名(票)] WHERE [条件]
DELETE FROMの後にテーブル名を指定し、WHEREで対象のレコードを指定します。
使い方:
今回は先程追加したIDが06のレモンのレコードを削除しようと思います。
DELETE FROM shohin where id = '06'
実行結果:

実行結果はこのように1行削除されたというメッセージが出ます。
ではSELECTして削除されているか確認してみましょう。
IDが06のレモンのレコードがテーブルから削除されているのを確認できました。
このようにWHEREで条件指定したレコードが削除できます。
注意:
DELETE 文ではWHEREで条件指定しなくても処理は通りますが、
テーブルのレコードを全てを消してしまいます。
以上になります。今回は初心者向けにSQL文の基本的な書き方を紹介しました。
SQLはシステム開発などにおいて必須と言っても過言ではないので
この記事をきっかけにSQLを学んで頂けたら幸いです。













